Webアプリケーションをはじめて開発する方に向けて、データベース設計の基本について説明していきます。データベースにはさまざまな種類がありますが、今回はテーブルによってデータを管理する「リレーショナルデータベース」を対象としています。
そもそもデータベース設計とは?
データベース
はじめに、データベースとは、決まった形式で整理・構造化された情報や、データの集まりのことをいいます。データを蓄積するだけではなく、抽出・編集・共有しやすくするためのもので、一般的には一連のテーブルの行と列で構造化されていることが多いです。この構造により、大量のデータに対する検索・閲覧や更新、管理および整理がしやすくなっています。
データベースについて、さらに知りたい方はこちらの記事を参考にしてください。
データベースとは?基礎知識と選び方
データベースソフト
データベースは、データを蓄積するための箱にあたるものです。実際にデータを利活用するためには、箱にデータをどのように入れるか、またどのように取り出すかを管理することが必要になります。
このような、データベースを管理するために必要なアプリケーションの集合体を、データベースソフトやデータベース管理システム(DBMS)と呼びます。
データベースソフトについて、さらに知りたい方はこちらの記事を参考にしてください。
データベースソフトとは
データベース設計
データベースソフトや管理システムを導入するだけで効率的なデータ利活用ができるかというと、そうではありません。データベースでデータを管理できるように、リアルの世界を抽象化し、どのような情報をどういった構造でデータベース化するのか設計することが必要です。このことを「データベース設計」(データモデリング)といいます。
データベース設計の良し悪しは、業務効率に影響します。適切にデータベースを設計することで、最新の情報や正確な情報へのアクセスが可能になり、データ利活用を促進するだけではなく、情報を探す時間を削減することで業務効率化が期待できます。
データベース設計の4大要素
データベース設計をする際に覚えておくべき4つの要素を紹介します。
エンティティ
データベース設計の対象業務において、管理すべき情報のことをエンティティといいます。管理すべき情報(エンティティ)を洗い出しすことで、設計ミスや手戻りのリスクを軽減し、効率よく品質の高いデータベースを設計することが可能になります。
たとえば、対象業務が販売管理の場合、顧客/商品/契約/注文/請求/在庫などがエンティティにあたります。”「顧客」が「商品」を購入する”という場合は、「顧客」と「商品」がエンティティです。
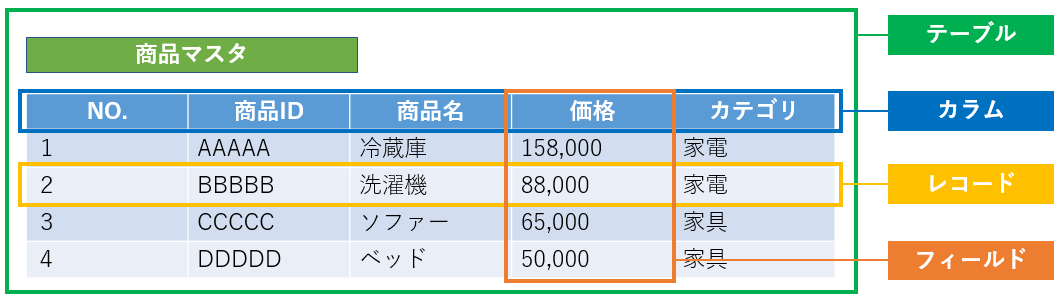
またエンティティはデータベースに含まれるテーブルのことを指します。※図
属性
あるエンティティに従属する項目のことを属性といいます。「従属する項目」とは、「エンティティを1つに定めたときに、一緒にわかる情報」のことで、たとえば、通販の商品カタログから欲しい商品を1つ選ぶとします。この際「商品名」や「価格」も同時に分かりますが、このような「商品」というエンティティに対し、一緒にわかる「商品名」や「価格」のような情報を属性と呼びます。
また属性は、データベース上のテーブルが持つフィールドのことを指します。※図
関係(リレーション)
結び付きのあるエンティティ同士を関連させるものを関係(リレーション)といいます。対象が顧客との契約を管理する業務の場合は、エンティティである「顧客」と「契約」同士が関係(リレーション)している状態です。
関係(リレーション)は、データベースに含まれるテーブルとテーブルをつなぐ共通の項目を指します。※図
※図:データベースのテーブルや各用語については以下図のように、Excelの表をイメージいただくとわかり易いです。
関連の多重度
関連のあるエンティティ同士の相対的な位置付けをより明確にするためのものを多重度といいます。関連の多重度はデータベース設計4大要素のなかでも、一番重要な要素と言っても過言ではありません。
相対的な位置づけとは、片方から他方を見たときに「相手が1つなのか、複数なのか」ということです。この関係性には次のような3つのパターンがあります。
- 「1対1」のパターン
たとえば、社員と社員番号の関係をみてみましょう。
それぞれの社員に対して社員番号が一意にふられる場合、社員側からみても、社員番号側からみても、1対1でそれぞれのエンティティが紐づくことがわかります。 - 「1対多、多対1」のパターン
たとえば、顧客と注文の関係をみてみましょう。
顧客側からみると、それぞれの顧客が複数回注文をすることがあるため、顧客に対して複数の注文が紐づきますが、注文側から見た場合、紐づく顧客は1つに固定され、みる側次第で相手のエンティティが1か多になります。 - 「多対多」のパターン
たとえば、社員と業務の関係をみてみましょう。
チームのように複数人で業務をおこなう現場であれば、社員に対して複数の業務が紐づくのと同時に、それぞれの業務に複数の社員が紐づき、どちらのエンティティからみても相手のエンティティが多になることがわかります。
発生する多重度のパターンに応じて、データベース設計時に考慮するべきエンティティが変わります。エンティティの考慮漏れが発生するとデータベース上でプロセスを表現できない場合があるため、多重度を決定するための過程は、エンティティの位置付けを明確にさせ、エンティティの抽出もれを防ぐことにつながります。
データベース設計のポイント5選
データベースを設計するうえで必要なポイントを5つ紹介します。
ポイントを踏まえて設計することで、最終的に、ニーズを満たし、変化にも柔軟容易に対応できるデータベースを構築できる可能性が高くなりますので、ぜひ参考にしてみてください。
構築するシステムの要件・仕様を理解しているか
データベース設計を進める上では、蓄積された情報を利用するためのシステムに関する要件や仕様を理解しておく必要があります。構築するシステムの要件・仕様を理解していなければ、そもそもデータベース上で用意するべきテーブルの種類やカラムを定義できないからです。
まずはどのような要件の、どのようなシステムを構築するのかをしっかりと理解し、そのうえで、要件定義書や外部設計書などをもとに情報を整理する方法がオススメです。要件定義書や仕様書を確認しながら大まかなテーブルを一旦洗い出し、次いで仕様書や外部設計書を確認しながら全体を見て調整することで、漏れなく適切な情報整理がしやすくなります。
仕様書から見えにくい箇所の想像ができるか
データの整合性や運用の観点で必要になりそうな項目を想像し検討する必要があります。たとえば、「すでに注文された商品を物理削除しても大丈夫なのか」や「いつ、だれが登録したデータなのか分からなくて大丈夫なのか」など仕様書に記載のない情報の必要性を検討しましょう。
物理削除されて困るテーブルには、論理削除フラグを設ける。いつ、だれが操作したレコードなのか後から追えるようにするために、登録日や登録者などの項目を持たせるというように、仕様書から見えにくい箇所も考えながらテーブル設計を進めます。
正規化がなされているか
正規化とは「テーブルを、可能な限り細かい、最小単位にしておく」という考え方です。基本的には、マスタデータとして再利用されやすいデータを別テーブルとして切り離して正規化をします。
たとえば、注文テーブルに「商品コード」と「商品名」のフィールドを作成したとします。しかし、別のテーブルで「商品コード」と「商品名」のフィールドが管理されていれば、注文テーブルには「商品コード」のフィールドさえあれば、一意に「商品名」も把握できるため、注文テーブルは最小単位になっていないといえます。
テーブルが最小単位になっていれば、レコードに更新があった際に1つのテーブルのレコードを更新すれば、関連するテーブルも同時に更新されるため、更新や管理の負荷軽減につながります。
正規化のメリット
- 冗長化を回避し、メンテナンス性が高まる(更新負荷が下がる)
- データの不整合を防ぐ
- マスタデータの使い回しなど拡張性があがる
- データ処理の効率がよくなる
将来性が考えられているか
対象業務の知見がある場合は、テーブルを設計している際に要件のヌケモレが見えてくることもあります。後々の手戻りを防ぐために、業務の担当者などに設計側の立場から提言や助言をもらうことをオススメします。
たとえば、設計当初は「商品」に紐づく「カテゴリ」が1つだとしても、事業が成長し、取り扱い商材が増えた場合には1つの商品に対して複数の「カテゴリ」を紐づける可能性は十分考えられます。
このような変化に備え、事前に中間テーブルを作成する、フィールドを設けておくなど、将来的にどのような管理が必要になるかを考えた設計をするとよいでしょう。
データベース設計の進め方
ここからは具体的な設計の進め方についてご紹介します。データベース設計は大きく、概念設計・論理設計・物理設計の3段階にわけられます。
概念設計
データベース設計の対象となる業務プロセスに必要なデータを抽出し、情報構造を抽象化して表現した「概念データモデル」を作成します。概念データモデルは、エンティティ(テーブル)と関連(リレーション)によって作成します。
論理設計
概念データモデルを整理し、使用するデータベースの種類に合わせた形に変換することで「論理データモデル」を作成します。安定したデータ構造を持ったデータベースを設計するために、データの重複をなくしたり、フィールドのデータ型を決定し、テーブルや列に対して制約を定義するといったこともこの段階でおこないます。
物理設計
論理設計で整理した情報をもとに、物理的なデータ配置を決定するだけでなく、パフォーマンスを考慮してデータベースを整理し、より現実的な「物理データモデル」を作成します。論理設計において正規化したテーブルの定義を崩したり、インデックスを定義したりして性能が向上するようにモデルを修正していきます。
このモデルをもって実際にデータベースによって管理することができる形式となります。
続いて、各設計段階の細かい手順をご紹介します。
概念設計1:データベースの目的・要件を決定する
設計作業全体を通して参照できる、完成度の高い判断指針を作ることで、目的に沿った意思決定がしやすくなります。
そのため、各ユーザーがそのデータベースをいつ、どのように使用するか、どのようなデータを管理したいのかを考慮し、データベースの目的を設定する必要があります。要件定義が不十分だと後で大問題につながるため、データベースを使用する対象の業務に求められる要件を整理しておくことが重要です。
概念設計2:必要な情報を整理してエンティティを抽出する
必要な情報を整理するには、既存の情報の洗い出しから始める必要があります。
たとえば、発注書の台帳や顧客情報などのドキュメントを収集し、含まれる顧客名、住所、電話番号などの情報を一覧表示することで洗い出しを行います。
後で調整できるため、最初から完璧を目指す必要はありません。頭に浮かんだものを順次列挙していきましょう。また、データベースを使用するユーザーがほかにもいる場合、そのユーザーにもアイデアを求めるとよいです。
既存の情報の洗い出しが完了したら、データベースから作成する可能性があるレポート、またはメールなどを念頭に、データベースに入れる必要のある情報を整理します。
既存の情報と将来必要になる情報をデータベース設計の4大要素を意識し整理しておきましょう。
概念設計3:ER図( Entity Relationship Diagram)を作成する
洗い出した情報をER図に落とし込みます。ER図のEはエンティティ(Entity)、Rはリレーションシップ(Relationship)の略です。つまりER図はエンティティとリレーションシップの組み合わせでシステムのデータやデータ間の処理構造を設計します。
ER図は以下の手順で作成します。
- 情報をテーブルに分割する
整理した情報のなかからエンティティを選択しテーブルを作成します。
この際、データベース設計のポイントを意識し、作成するテーブルは可能な限り細かい、最小単位にしておきます。 - 情報の項目をフィールドに変える
整理した情報のなかから属性を選択しフィールドを作成します。
名前を姓と名で分けるかなど、データの活用を意識してフィールドは調整します。また、フィールドを作成する際は「計算されたデータは入れない」「情報は最小限の論理単位で格納する」ことを意識するとよいです。 - 主キーを指定する
各テーブルには、IDやシリアル番号など、テーブルに格納されている各行を一意に識別する列を含める必要があります。
データベース用語では、この情報をテーブルの主キーと呼びます。 - テーブル リレーションシップの作成
意味のある方法で情報を再度結合するため、リレーションシップを作成します。
たとえば、顧客の注文情報を管理する場合、顧客テーブルと注文テーブル、商品テーブルを関連付けます。
論理設計1:正規化をおこなう
テーブルの構造が正しいか確認するために、データの正規化ルールを適用します。情報項目を正しいテーブルに分割したかを確認することができるため、すべての情報項目を表現し、仮の設計に到達した後に実施すると便利です。
正規化ルールは、設計が “正規形” と呼ばれる形式になることを確認するまで連続して適用します。
正規形には、広く知られているもので第1正規形から第5正規形までありますが、ほとんどの場合第4正規形以降は実務では使用しないため、第3正規形まで確認できれば良いでしょう。
物理設計1:データ型を決定する
データを保存する際のデータ型を属性ごとに決定します。たとえば、「商品コード」は文字列として保存するか数値型で保存するかなど、データベースの目的に合わせてデータ型を決定しましょう。データ型の種類はシステムによって異なる場合があるため、利用するシステム要件を確認のうえ、最適なものを選択します。
物理設計2:設計を確認・調整する
必要なテーブル、フィールド、リレーションシップをシステム上に作成したら、実際の業務を想定したサンプルデータを作成してテーブルに入力し、想定とおりの操作となるか試します。列の挿入漏れや、テーブルを分割する必要がある場合など、業務遂行時に必要な設計の考慮が見つかるので、試行と調整を繰り返します。
またこの際、性能要件も確認します。たとえば1日や年間でどのくらいのデータが追加されるのかといった容量や、一度にどのくらいのアクセスがあるのかといった内容を確認し、それらの情報から、業務を円滑に進めるためにはネットワークやハードウェアにどのくらいの性能が必要なのかを確認します。確認した性能要件にあわせて、インデックスの追加やあえて正規化を崩すことでパフォーマンスの向上を図ります。
まとめ
いかがでしたか?
データベース設計は、利用するデータベースの種類や仕様、対象業務の内容やシステム要件によって留意すべき点に違いがあるため、決まった正解がありません。しかし、要件に沿ってしっかりとしたデータベース設計をおこなうことが、その後の業務効率化やデータの正しい管理に貢献することがイメージいただけたかと思います。
ドリーム・アーツでは、Webデータベース機能を備え、データベースソフトとして利用できる「SmartDB」を提供しています。ノーコード開発基盤なので、ドラッグ&ドロップや簡単な設定変更のみで業務アプリケーションを作成できます。現場部門(非IT部門)の方でも簡単に業務デジタル化を実現できるので、業務効率化を検討している方はぜひご覧ください。
今さら聞けない「Webデータベース」の話関連資料

3分でわかる「SmartDB」
大企業における業務デジタル化の課題と、その解決策として「SmartDB」で、どのように業務デジタル化を実現できるのかをご紹介する資料を公開しました。ぜひご覧ください。
詳細・お申し込みはこちら

この記事の執筆者:冨田(マーケティンググループ)
2013年新卒入社。文系出身でプログラミング未経験者ですが、過去にさまざまな業務・業種・立場の方のお客さまの電子化/デジタル化を支援いたしました。その経験を通じてSmartDB(スマートデービー)があらゆる企業の業務の効率化に貢献できると感じています。ITスキルがない人でも「自分たちの業務も自分たちで電子化/デジタル化できる!」ということを実感してもらえるよう、いろいろ検討中です。“自分たち”で“自分たちの業務”の業務で利用するシステムを改善できる楽しみをお伝えしていきます。